In this post I want to write about Information retrieval. Spotlight is a selection-based search system, which creates a virtual index of all items and files you want.
we must solve the following problem:
We have a lot of PDF described by the text they contain or also images/videos described using TAGS. Spotlight allow the user to quickly locate a wide variety of relevant items that contain , with high probability, the informations you are looking for.
We will use:
An Information Retrieval System (IRS). It is a system designed and built to perform tasks of Information Retrieval for big collections of documents, it ensures decription of documents and retrieval of those considered relevant to the needs expressed by the user ’s questions.
Let’s start with some Theory:
Let:
di = (wi1, …, wik)
be the vectorial rappresentation of a document.
wij is the weight of descriptor tj in document di
Right now let’s say that a descriptor is a single word in a document (PDF).
Now we choose a weight schema that’s called TF (Term Frequency).
wij = fij
Where fij is the number of times descriptor tj appear in document di
Let:
D1 = {a, a, a, b, b, c}
D2 = {a, a, b, c}
D3 = {a, b, b, c}
D4 = {a, b, d}
Our Query is Q = {a, c, d}
Q D1 = {4} Q D2 = {3} Q D3 = {2} Q D4 = {2}
Won D1 and D2 becouse “a” appears several times in each. BUT IT APPEARS IN ALL DOCUMENTS!!!
The Presence of d in our query can not discriminate D4
We must define a schema IDF (Inverse Document Frequency)
wij = log (N/nj)
N is the number of documents in our collection.
nj is the number of documents, of the whole collection, where the descriptor tj appear.
So our search Engine will return D4.
If a descriptor appear many times in all documents then it loses importance in the description of documents.
The schema that we will use is a combination of schema explained in this post. Its name is TFIDF
wij = fij log (N/nj)
Long documents contains relevant descriptors many times than short documents. Our search Engine will give more importance at first .
In your CoreData Project open .xcdatamodel and add the following table:
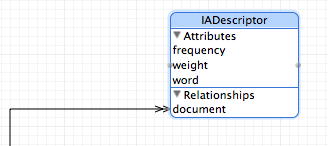
It describes:
– the word field
– the frequency of the word
– the weight of the word
– A Relation (with Inverse) to your Documents Table.
In a document there are a lot of words that are not useful for our purposes, becouse they don’t describe the content of our documents. That words are articles, some adjectives and so on… In the following Link you can find two list of words that I prepared in Italian and English. They’re called STOP WORDS.
1) Read both files in two NSString:
NSString englishStopWords <– stop-words-eng.txt
NSString italianStopWords <– stop-words-ita.txt
Now split them in an array
1
2
NSArray stopWordsITA = [italianStopWords componentsSeparatedByCharactersInSet:[NSCharacterSet characterSetWithCharactersInString:@" \n"]];
NSArray stopWordsENG = [englishStopWords componentsSeparatedByCharactersInSet:[NSCharacterSet characterSetWithCharactersInString:@" \n"]];
2) Get Your document’s text ans save it in a dictionary where a word is the key and the value is the frequency of that word in the Document.
3) Filter the dictionary ad remove all stop words. You can also filter the dictionary’s representation of a document with the stopwords while you are creating it
4) Describe your document in a DB (ex. NSManagedObject is IADocument class)
5) Save the descriptor for that document
6) Now keeping reference at what we explained at the beginning of this post create your retrieval function